Why our AI Asks Fewer Questions (and Gets Better Answers)
What a 12,000-indication landscape taught us about building multi-agent biopharma analysis systems

The problem with brute force
The best AI model cannot fit a whole problem like this in its head — that is, its context window — at once. And if it could, the results wouldn't be spectacular. Why? Because a problem like this requires specific reasoning over thousands of different data points, and LLMs are known to miss critical information buried in long contexts [1], suffer from context rot as input tokens scale [2], and drift from their original goal over extended tasks [3, 4].
An alternative is to chunk the landscape and have the LLMs evaluate each piece in isolation, but the decisive questions here are comparative (e.g., how does the efficacy data for asset A compare to that of asset B), so a single-pass method won't work.
For AI to be effective at taking this all into account, it needs a structured, methodical approach. So we ran an experiment: we built a multi-agent system that is selective — it only looks at the questions it must look at, when it needs to look at them. For massive landscape analyses, doing less lets us do more.
Not every question deserves an answer
So how do you decide what indications to look at? It's not a data problem. Sleuth has all the data an AI needs to make these individual judgments on a per-indication basis, and we have it indexed so the AI can always find what it needs. An AI hooked up to our data can evaluate the relevant sub-questions, individually, across the entire space of indications. But we're looking for five out of 12,000 (0.04% of the landscape) across more than a dozen criteria. The trouble is, doing this for all questions is at best an inefficient approach, and at worst an ineffective one. Even if we answer every question, we still have a decision to make. The AI is still stuck with how to decide, from this mass of data, which indications are best. Collecting and curating the data isn't the bottleneck. Deciding what to query, and in what order, is the actual engineering problem.
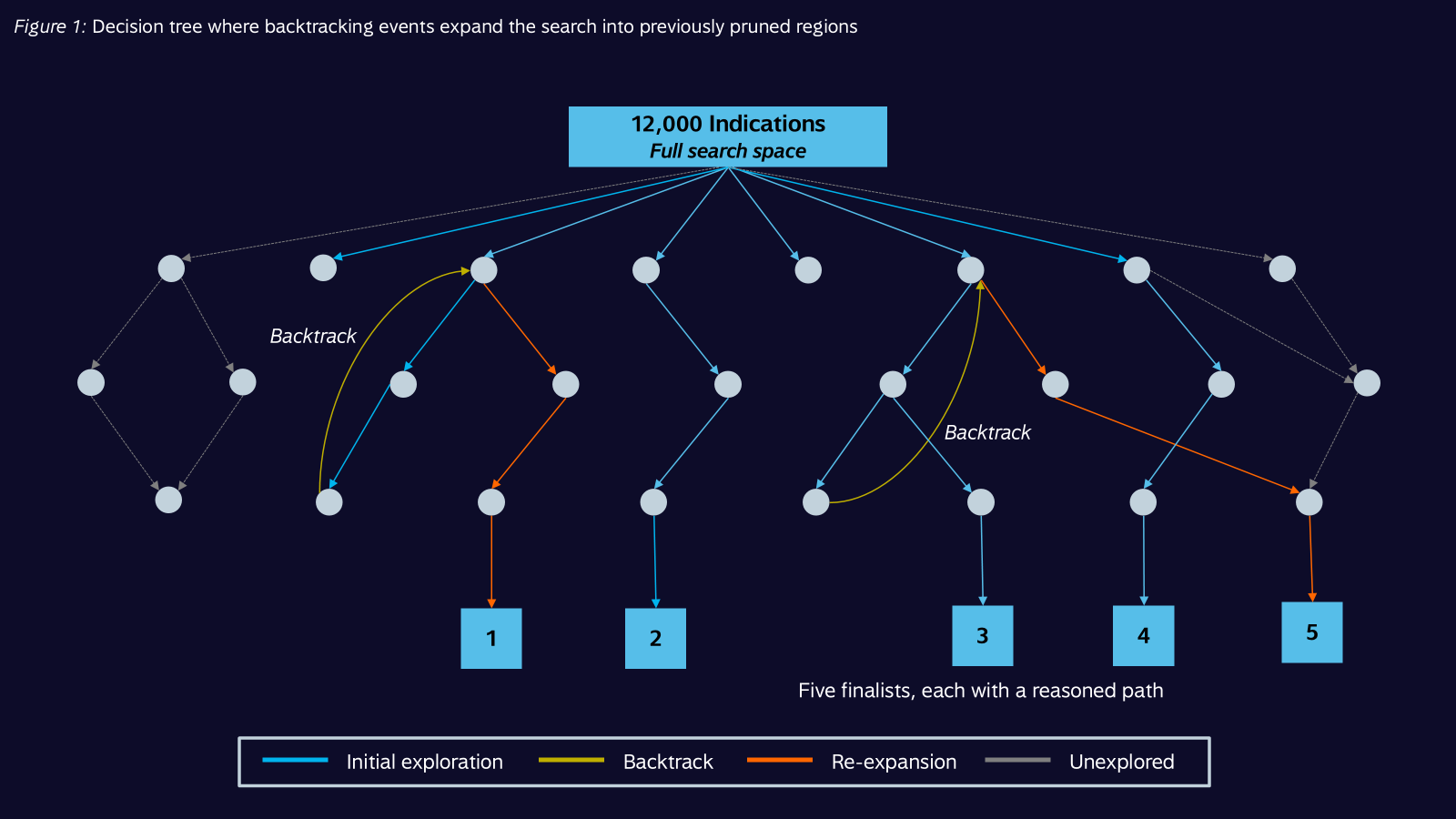
First lesson: the AI really shouldn't ask every question of every indication. This just creates a lot of noise to sift through, leading to misselection and drift. Moreover, the answer to any one question can rule out many indications from consideration. We experimented with treating the problem as a decision tree: at each branching, the AI narrowed down which indications still made sense exponentially. By the end of the full process, this selective approach required roughly 95% fewer agent calls than brute-force traversal would have.
Build the system to second-guess itself
Using just one of the primary biological factors, the system was able to rule out 94% of the indications immediately. In doing so, a few important ones the client had flagged disappeared. The AI had interpreted the biological factor too rigidly and conservatively, judging certain indications as unlikely to meet a required threshold when, in fact, they might. So we had to bring them back.
Second lesson: our cuts of the data must be tentative. The AI must be able to correct itself. We realized the system needed to apply backtracking search and constraint satisfaction. As it narrowed the field, if plausible candidates started disappearing, it could adjust thresholds for the next cut or selectively re-run its own judgments with different assumptions. For decision trees to be most effective as classifiers, they need to consider not just different thresholds but different possibilities for traversal. It might, for instance, be better to first ask whether the drug is good at targeting cells in different organs, before asking how efficiently it delivers its effect on cells.
Better questions, every time
When we enabled all these capabilities, the landscape agent delivered a set of five indications that made every cut, and for each one, a well-reasoned path that clearly explains why. It also generated a record for the paths that didn't make it: how things were ruled out early on, summaries for larger cuts, the whole final decision tree. All of this was presented to an analyst agent, which produced the final output — executive summary, slide decks, insights and recommendations — grounded in a real understanding of how everything fits together.
Third lesson: cache what you learn across agents. Every time a system like this runs a decision tree, it should retain what it learned at two levels: generalizable analytical patterns that improve every future analysis (e.g. which traversal strategies work), and client-specific learnings that make that client's next output sharper (e.g. which biological factors mattered for their pipeline).
The next time a client asks a similar question, the system starts smarter. The richness of our data and the insights possible from it grow over time as a natural result of the work we do.
Facing a similar landscape question? Talk to us about how Sleuth can narrow your search.
References
[1] Liu et al., "Lost in the Middle: How Language Models Use Long Contexts" (2024, Transactions of the ACL, Vol. 12). The foundational paper. Shows LLM performance degrades significantly when relevant information sits in the middle of long contexts — a U-shaped accuracy curve. arxiv.org/abs/2307.03172
[2] Chroma Research, "Context Rot: How Increasing Input Tokens Impacts LLM Performance" (July 2025). trychroma.com/research/context-rot
[3] Anthropic, "Effective Context Engineering for AI Agents" (September 2025). anthropic.com/engineering/effective-context-engineering-for-ai-agents
[4] "Technical Report: Evaluating Goal Drift in Language Model Agents" (2025, arXiv). Directly evaluates goal drift in LLM agents over extended tasks, showing models deviate from system goals, especially under adversarial or competing-goal conditions. arxiv.org/abs/2505.02709